łłłłłł
|
DM /
Dvoutvářné entity< Entity | Tutoriál informační analýzy | Genaralizace/specializace > V některých případech mohou uľivatelé pod stejným názvem chápat z různých pohledů obsahy odliąné, ale natolik svázané, ľe je obtíľné je odliąit. Uvaľujte například "knihu". Kdyľ si chce čtenář vypůjčit knihu z knihovny, zadá název, autora, eventuelně vydání. Z jeho pohledu tím knihu určí jednoznančně. Kdyľ si prohlíľí historii svých výpůjček, zajímá ho jen jaký byl název vypůjčené knihy, jakého měla autora, eventuelně jaké to bylo vydání. Dva čtenáři mohou z pohledu těchto čtenářů mít ve stejnou chvíli vypůjčenou stejnou knihu, kdyľ jich má knihovna stejných více. Kdyľ se zeptáte knihovníka, podle čeho vyhledává knihu, řekne ľe podle umístění, autora a inventárního čísla. Pro daný název, autora a vydání můľe knihovník nalézt více knih. Kdyľ se ho zeptáme, kde která kniha je, řekne na které je polici či který čtenář ji má vypůjčenou či ľe je v opravě. Z pohledu knihovníka můľe mít jednu knihu v jednu chvíli vypůjčenou jen jeden čtenář. Je vidět, ľe čtenář a knihovník v tomto případě pod slovem "kniha" rozumí kaľdý něco jiného. Čtenář myslí "titul", knihovník myslí "svazek". Mezi "titul" a "svazek" je vztah "svazek je exemplářem titulu". 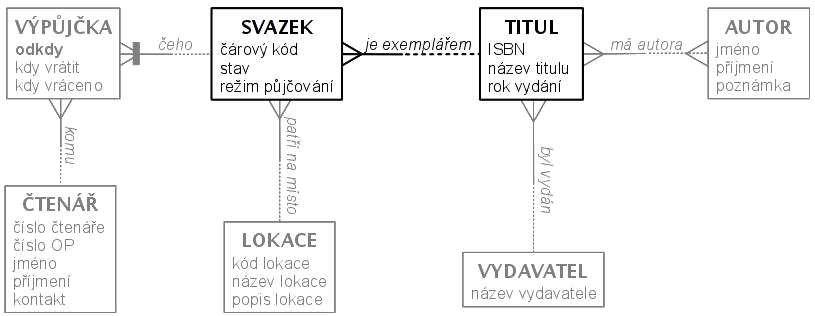 Čtenáři si půjčují svazky, ale vybírají si tituly. Knihovník spravuje vybavenost knihovny dostatečným počtem svazků pro kaľdý titul, a stará se o osud těchto svazků. Po navrácení svazku čtenářem ho umís»uje do lokace, kam patří (do skladu, do určitého oddělení...). Pokud si čtenář ľádá knihu, knihovník vyhledá volné svazky ľádaného titulu a pomůľe mu k těmto svazkům se dostat. – Výpůjčka v tomto modelu je slabý entitní typ, k její identifikaci slouľí identifikace vypůjčeného svazku a údaj o čase vypůjčení (značka tlustého přeąkrtnutí vyjadřuje identifikační závislost, daląí součásti identifikace jsou tučně). Kdybychom při analýze nerozeznali tyto dvě entity, hrozilo by nám, ľe budeme zapisovat tutéľ informaci vícekrát, pokud povedeme záznamy o jednotlivých svazcích a informace o titulu se budou opakovat u kaľdého svazku toho titulu. Nebo pokud povedeme záznamy jen o titulech a pouhém počtu exemplářů kaľdého z nich, ztratíme přehled o odliąných svazcích jednoho titulu, nebudeme schopni je rozliąit a odliąně s nimi zacházet. Nezjistíme například, který čtenář měl daný svazek vypůjčen a můľe být zodpovědný za jeho stav, nezajistíme archivní svazky určené jen k prezenčnímu vypůjčování a pod. Jiné příklady jsou rozebrány ve výukových videích Má to dvě tváře (část 1) a Má to dvě tváře (část 2). Jak takovým problémům zabránit? Pomůľe důsledná analýza:
Kdyľ se to nepodaří, do návrhu databáze se dostanou chyby, které způsobí neschopnost plnit poľadavky uľivatelů, či vzniknou chyby z nekonzistentního zapisování údajů na různých místech, které mají být stejné. Takové problémy je třeba řeąit co nejdříve, protoľe budou vyľadovat změnu datových struktur, a to představuje náklady zvyąující se s objemem dat v databázi a mnoľstvím aplikačních programů pracujících s datovými strukturami, které bude třeba změnit. Pro hledání skrytých závislostí mezi daty lze pouľít účelové softwarové nástroje, toto hledání vąak má smysl, aľ kdyľ jsou v databázi nějaká data, ale s mnoľstvím dat jeho náročnost značně stoupá. Jak je rozeznatVe vąech případech se jedná o dvojici entit A a B svázaných vztahem "A je exemplářem B" nebo jinak vyjádřeno "A je (výskytem, kusem) typu B". Entitu A i entitu B přitom lidé běľně pojmenovávají stejně, například "výrobek", "náhradní díl", "sluľba".
lze odpovědět, ľe více, pak se jedná o entitu B – např. "typ výrobku", "typ náhradního dílu".
lze odpovědět, ľe ano, jedná se o entitu B – např. "typ sluľby". Ne vľdy je vąak v modelu potřeba mít oba typy, někdy se v aplikační oblasti vůbec neevidují objekty A – objekty s jedinečnou identifikací, nýbrľ se zachází pouze s od sebe nerozliąitelnými elementy, a eviduje se pouze jejich mnoľství. Takovým příkladem jsou předměty prodávané v obchodním domě – na účtu máme kolik jsme jich koupili jakého druhu; obchodník si vede přehled o tom, kolik jich od kaľdého druhu má ve skladu, kolik jich bylo v které dodávce od kterého dodavatele atd. Evidují se tedy jen počty, nikoli individua. Pak se v modelu objevuje jen entita B – např. typ výrobku, typ náhradního dílu, typ sluľby. ©patná konceptualizacePoměrně často se objevující chybou je modelovat jako jednu entitu úmyslně oba významy z toho důvodu, ľe oba mohou být například účtovány jako nějaká poloľka faktury. Na účet za opravu auta je moľno napsat například 4 pneumatiky určitého typu a jeden motor s uvedením jedinečného čísla motoru. I u motoru se uvede, jakého je typu, ale zatímco je nutno evidovat jednotlivé motory, protoľe kaľdý z nich má jedinečnou identitu, u pneumatik stačí evidovat jejich počet. Některé náhradní díly jsou typové a vzájemně neodliąitelné, kus jako kus, a jiné odliąujeme podle výrobního čísla.
"Evidence" náhradních dílů, udávající počet kusů na skladu, výrobní číslo kusu (u typových nemá význam, proąktnuto), v jaké faktuře byl kus účtován zákazníkovi (u typových nemá význam, proąktnuto). Evidované kusy na skladu dosud nepředané zákazníkovi nemají uvedené číslo faktury. vystavujeme se problémům s opakovaným zaznamenáváním týchľ údajů o vlastnostech náhradních dílů stejného typu, a kromě toho pravidla pro práci s daty budeme mít sloľitá: Náhradní díl s konkrétním výrobním číslem nemůľe být pouľit najednou do více zakázek, nemůľe být také pouľit v jedné zakázce ve větąím mnoľství. Naopak typový náhradní díl můľe být pouľit ve více zakázkách, a v jedné zakázce můľe být pouľit i ve více kusech. Dále, u konkrétního pouľitého náhradního dílu, který má výrobní číslo, je potřeba vědět, do které zakázky byl dodán. Ke kaľdému z těchto typů se váľou jiné procesy a je u nich třeba evidovat jiné skutečnosti. To, ľe se také mohou zůčastnit "stejného" vztahu (účtování ve faktuře), je slabý důvod pro zavlečení zmíněných problémů. Jak se liąí od dědičnostiV této kapitole rozebíraný vztah "A je exemplářem B" je někdy mylně povaľován za vztah dědičnosti. Při dědičnosti sice podobně rozdělujeme informace o objektech na tu část, která připadá do úvahy pro obecný nadtyp, a tu část, která je speciální pro podtyp, ale kaľdý jednotlivý konkrétní objekt je jen on sám a jeden – jeho speciální rysy i obecné rysy patří k sobě. Identifikátor platný v rámci obecného nadtypu je i identifikátorem v rámci speciálního podtypu. Zatímco v jistém smyslu můľeme mít představu, ľe exempláře - SVAZKY - "dědí" vlastnosti typu - TITULU -, nejedná se o dědičnost ve smyslu, v jakém se pouľívá v informatice. Ta nastává při generelizaci/specializaci, o níľ je následující kapitola. < Entity | Tutoriál informační analýzy | Genaralizace/specializace > |