łłłłłł
|
DM /
Generalizace/specializace< Dvoutvářné entity | Tutoriál informační analýzy | Co jsou ISA vztahy > V autoopravně účtují práci a náhradní díly. Práce jsou různého druhu s různou hodinovou sazbou. Náhradní díly mají cenu podle ceníku nebo podle ceny dodavatele, některé má dílna na skladě, jiné objednává v případě potřeby. Rozliąují se jeątě náhradní díly, jeľ mají speciální evidenci jednotlivých kusů, jako motory, od náhradních dílů, u kterých se jednotlivé kusy nerozliąují a eviduje se jen jejich počet. Práci i náhradní díly lze povaľovat za "sluľby" poskytované zákazníkům. U "sluľby" známe její cenu, a lze ji účtovat ve faktuře, s udáním účtovaného mnoľství – počtu hodin práce nebo počtu kusů. O náhradních dílech, a» uľ typových, nerozliąujících jednotlivé kusy, tak o náhradních dílech s evidencí jednotlivých exemplářů, je třeba znát informace o názvu náhradního dílu, objednacím kódu, dodavateli, technických parametrech a pod. Pojem "náhradní díl" je srozumitelný a v kontextu autoopravny pouľívaný. Generalizace či specializace je to co děláme v průběhu datového modelování, tyto procesy ve výsledku oba vedou k analogii mnoľin a jejich podmnoľin: při generalizaci vytváříme nadtyp (alà nadmnoľinu), při specializaci podtypy (alà podmnoľiny). Následující obrázek znázorňuje prve zmíněné typy a jejich podtypy: 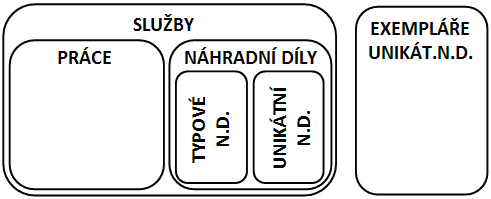 Entitní typy jako mnoľiny Eulerův diagram pro entitní typy "sluľba","práce","náhradní díl", "typový náhradní díl", "typ unikátního nahradního dílu" a "exemplář unikátního náhradního dílu" Následující diagram přidává atributy a vztah unikátních exemplářů k přísluąnému typu náhradního dílu: 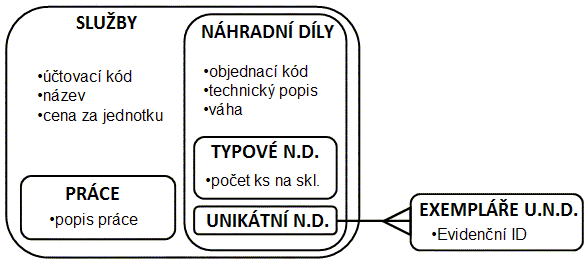 Entitní typy a podtypy s atributy a vztahy Odráľkovaný seznam uvnitř zaobleného obdélníku vyjmenovává atributy zahrnuté v infomodelu pro daný entitní typ. Spojnice mezi zaoblenými obdélníky "unikátní náhradní díly" a "exempláře unikátních náhradních dílů" představuje vztah náleľení exempláře k typu. Takľe kaľdá sluľba má kód sluľby, název a jednotkovou cenu, kaľdá práce má navíc popis práce. Náhradní díly mají kromě kódu sluľby, názvu a jednotkové ceny jeątě objednací kód, technický popis a váhu. Typové náhradní díly mají navíc jeątě počet kusů na skladu. Typy unikátních náhradních dílů nemají navíc ľádný atribut, ale mají vztah k evidenci jednotlivých kusů toho typu. V grafickém zobrazení konceptuálních schémat se často pouľívá znázornění kaľdého entitního typu zvláą», i kdyľ se jedná o podtypy a nadtypy. V takovém zobrazení není podtyp umístěn uvnitř nadtypu, ale mimo. V zobrazení se pak objeví daląí vztahy (tzv. ISA vztahy), které znázorňují, ľe kaľdý výskyt v podtypu je zároveň výskytem i v nadtypu. Název ISA pochází z anglického "is a", například "kaľdá PRÁCE je SLU®BA" = "each WORK is a SERVICE". ISA vztahy se znázorňují ąipkami od podtypu k nadtypu. (Podrobněji je otázka těchto obtíľněji pochopitelných vztahů diskutována v kapitole Co jsou ISA vztahy.) Následující obrázek zobrazuje předchozí konceptuální schéma s pomocí ISA vztahů: 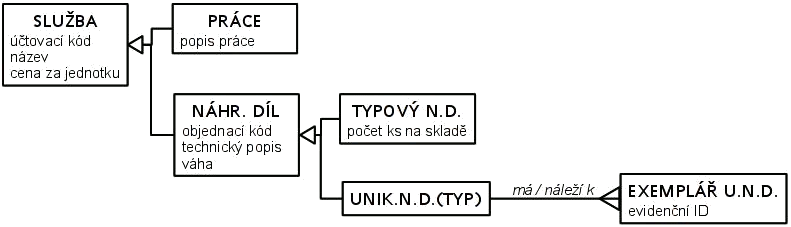 ISA vztahy mezi entitními typy Kaľdá PRÁCE je zároveň SLU®BA, kaľdý NÁHRADNÍ DÍL je zároveň SLU®BA, kaľdý TYPOVÝ NÁHRADNÍ DÍL je NÁHRADNÍ DÍL, kaľdý UNIKÁTNÍ NÁHRADNÍ DÍL(TYP) je NÁHRADNÍ DÍL. Vztah mezi exemplářem unikátního náhradního dílu (EXEMPLÁŘ U.N.D.) a přísluąným typem unikátního náhradního dílu (UNIK.N.D.(TYP)) není ISA, je to vztah mezi typem a výskytem, jak o tom pojednává kapitola Dvoutvářné entity. Rozdíl je v tom, ľe k jednomu typu unikátního náhradního dílu (UNIK.N.D.(TYP)) můľe náleľet více jeho exemplářů (EXEMPLÁŘ U.N.D.). Ale jedna SLU®BA je buď jedna a ne více PRACÍ nebo jeden a ne více NÁHRADNÍCH DÍLŮ. Identifikátory v rámci generalizace a specializaceS identifikátory je to jiné, pokud k nadtypům a podtypům dojdeme generalizací, neľ kdyľ k nim dojdeme specializací. Začněme specializací, protoľe v tom případě je to jednoduąąí. Pokud v rámci nadtypu platí nějaké identifikační schéma, platí i v rámci kteréhokoli jeho podtypu. Takľe objednací kód platný jako identifikátor libovolného TYPU NÁHRADNÍHO DÍLU je samozřejmě identifikátorem i v omezeném rámci TYPOVÝCH NÁHRADNÍCH DÍLŮ i v rámci TYPŮ UNIKÁTNÍCH NÁHRADNÍCH DÍLŮ. Při specializaci nově vzniklé podtypy dědí i způsob identifikace nadtypu. Pokud účelově generalizujeme vzájemně dosti nepodobné entitní typy, jako například PRÁCI a NÁHRADNÍ DÍL, pak nám větąinou nezbývá neľ uměle vytvořit nový identifikátor pro nově vytvořený nadtyp. Typ SLU®BA je takový případ, a účtovací kód je příklad uměle vytvořeného identifikátoru. Potřeba takového identifikátoru plyne z potřeby se odkazovat na výskyty toho generalizovaného nadtypu jednotným způsobem, jako v tomto případě odkazovat poloľky na fakturách zákazníků do seznamu účtovatelných SLU®EB. Je sice moľno se obejít bez vytvoření takového umělého identifikátoru, ale řízení přístupu k datům se s takovým identifikátorem značně zjednoduąí. V rámci některých podtypů v takových případech obvykle platí nějaké původní identifikátory (pouľívané jiľ před generalizací), jako například objednací kód NÁHRADNÍCH DÍLŮ. Pro takový podtyp pak máme alternativní způsoby identifikace – účtovací kódy i objednací kódy mohou kaľdý z nich stejně dobře slouľit k identifikaci NÁHRADNÍCH DÍLŮ. Členění a rozčleňující charakteristikaČlenění je speciální případ rozdělení nadtypu do několika podtypů tak, ľe toto rozdělení je úplné a kaľdý výskyt nadtypu se vyskytuje pouze v jediném z těch podtypů. U rozdělení SLU®EB na PRÁCE a NÁHRADNÍ DÍLY v předchozím případě sice tomu takto je, ale můľeme to chápat jako přechodný stav. Lze si představit, ľe autoopravna zařadí do seznamu nabízených sluľeb jeątě jiné sluľby, například zprostředkování prodeje či vytipování koupě ojetého automobilu. TYPY NÁHRADNÍCH DÍLŮ jsou vąak typický případ. U konkrétního typu náhradního dílu buď vedeme evidenci jeho identifikovaných exemplářů, nebo ne. Jasně jiná moľnost není, a tyto moľnosti se vzájemně vylučují. Takľe to, zda se u daného typu dílu vede evidence jednotlivých kusů, je rozčleňující charakteristika do daných dvou podtypů TYPOVÝ NÁHRADNÍ DÍL a TYP UNIKÁTNÍCH NÁHRADNÍCH DÍLŮ. Jiný příklad tvoří rozdělení osob podle biologického pohlaví na ľeny a muľe. Pohlaví je rozčleňující charakteristika, kaľdou osobu podle ní zařadíme buď mezi muľe nebo mezi ľeny. Takovýto jasný znak, podle kterého se nadtyp člení do podtypů, je moľno v konceptuálním schématu zachytit: 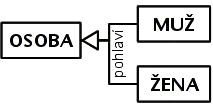 RoleStudenti a učitelé na vysoké ąkole jsou osoby. Kromě studentů a učitelů zde pracují daląí lidé – administrativní pracovníci, pracovníci technické podpory a údrľby. O kaľdé osobě se evidují její osobní data, tj. jméno, příjmení, adresa atd., i veřejnosprávní identifikátory – rodné číslo, číslo občanského průkazu nebo pasu. Pojem "osoba" lidé běľně uľívají, při analýze má smysl uvaľovat ji jako samostatnou entitu: ke kaľdé osobě se váľe daląí informační obsah, například číslo univerzitního průkazu, přístupové jméno a heslo do počítačové sítě ąkoly, "osoby" se stravují ve ąkolní menze, účastní se ąkolou organizovaných akcí, půjčují si ąkolní majetek, vyuľívají sluľeb ąkolních zařízení. 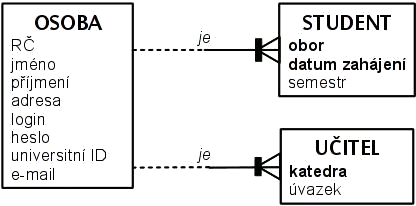 Typy bez evidovaných instancíUvaľujme ovoce. Jahody, maliny a hruąky jsou ovoce. O kaľdém druhu ovoce můľeme například uvést barvu, průměrnou váhu jednoho kusu, kdy a kde dozrává. "Ovoce" je proto vhodný kandidát na entitní typ. "Jahoda","hruąka","malina" vąak podtypy nejsou, neevidujeme jednotlivé kusy těchto druhů ovoce, jsou to exempláře typu nazvaného v předchozí větě "ovoce", ale výstiľnějąí by bylo nazvat tento typ "druh ovoce" . < Dvoutvářné entity | Tutoriál informační analýzy | Co jsou ISA vztahy > |